python multiprocessing多线程爬虫怎么写
1、假如我们要访问100次百度首页,用传统方法是这样的:
import requests
for x in range(100):
res = requests.get('https://www.baidu.com')
print(res.status_code)#这一行是为了确保程序在运行输出响应码,可以删掉
我们用time模块计算所需时间:
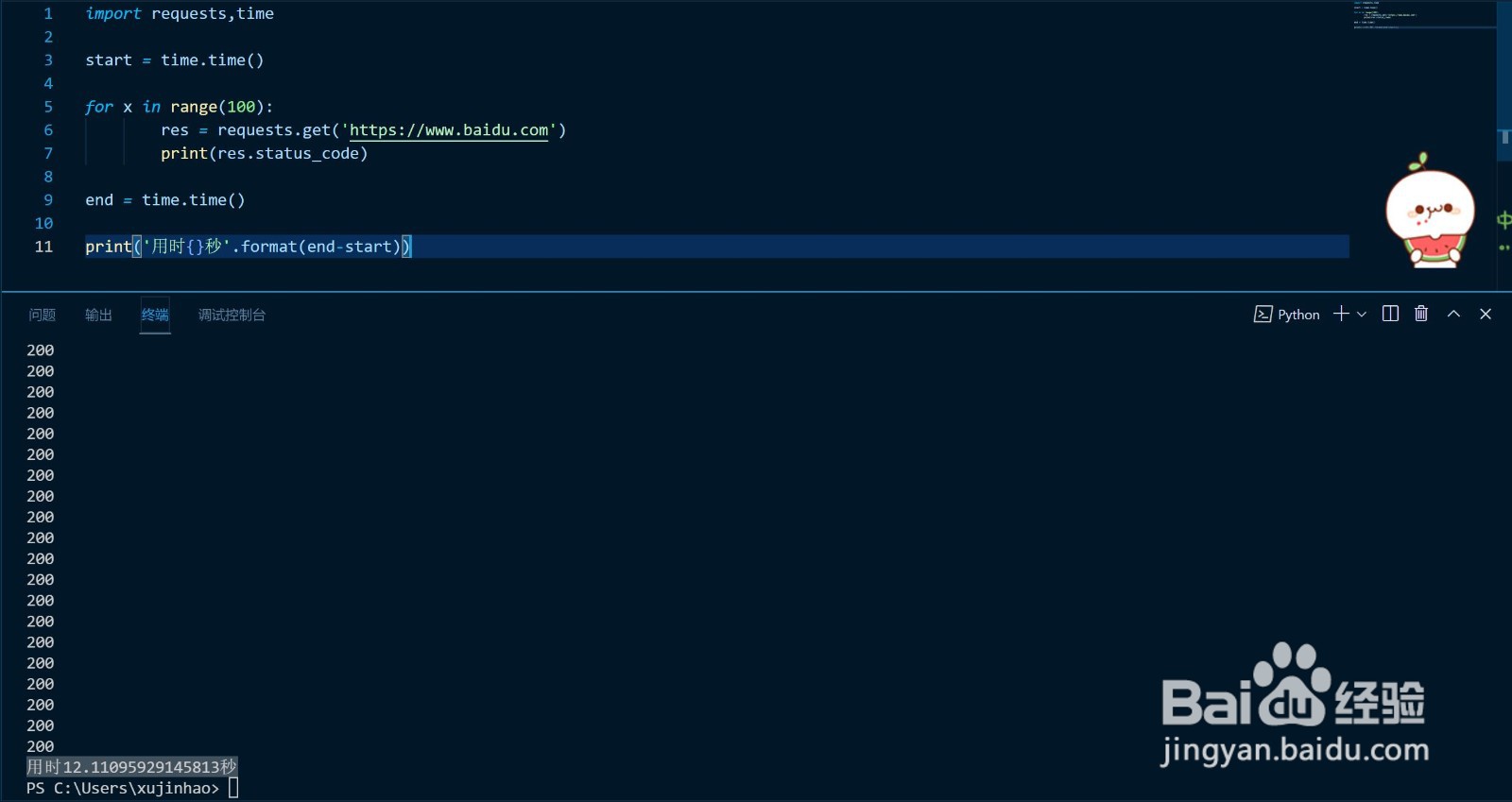
import requests,time
start = time.time()
for x in range(100):
res = requests.get('https://www.baidu.com')
print(res.status_code)
end = time.time()
print('用时{}秒'.format(end-start))
它的输出结果为 用时12.11095929145813秒≈12s
2、12秒多,虽然可以接受,但如果要访问1000次、10000次呢?小编测试了一下1000次的结果约为118s,约两分钟,太慢了。把它封装成函数:
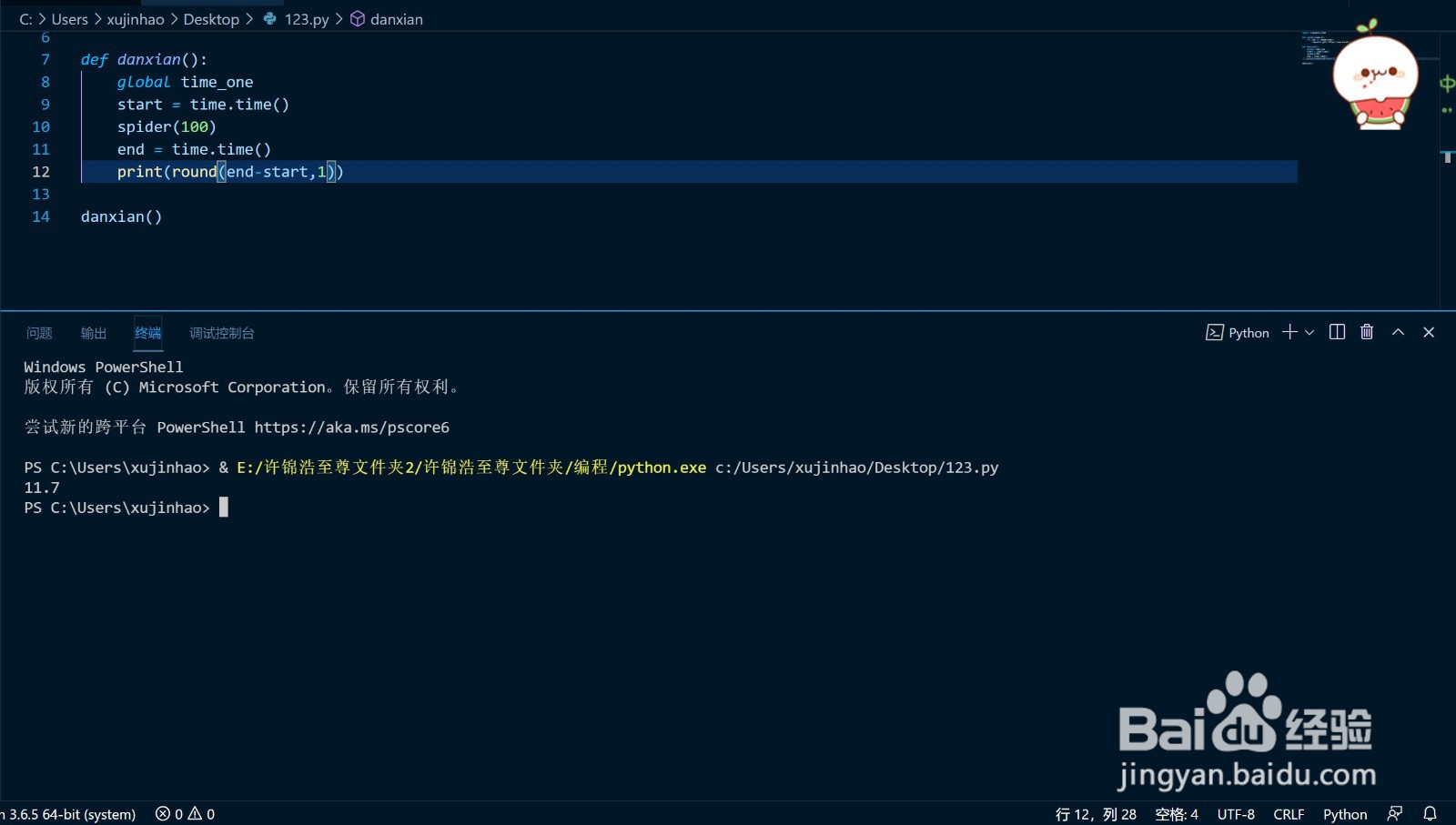
import requests,time
def spider(nums=1):
for num in range(nums):
requests.get('https://www.baidu.com')
def danxian():
start = time.time()
spider(100)
end = time.time()
print(round(end-start,1))
danxian()
3、多线程库:multiprocessing
当然多线程库还有gevent等,但multiprocessing最简单、最简短,请先pip安装。(pip3 install multiprocessing)
下面是计算1~9乘方的代码
单线程:
for x in range(10):
print(x**x)
结果:
1
1
4
27
256
3125
46656
823543
16777216
387420489
多线程:
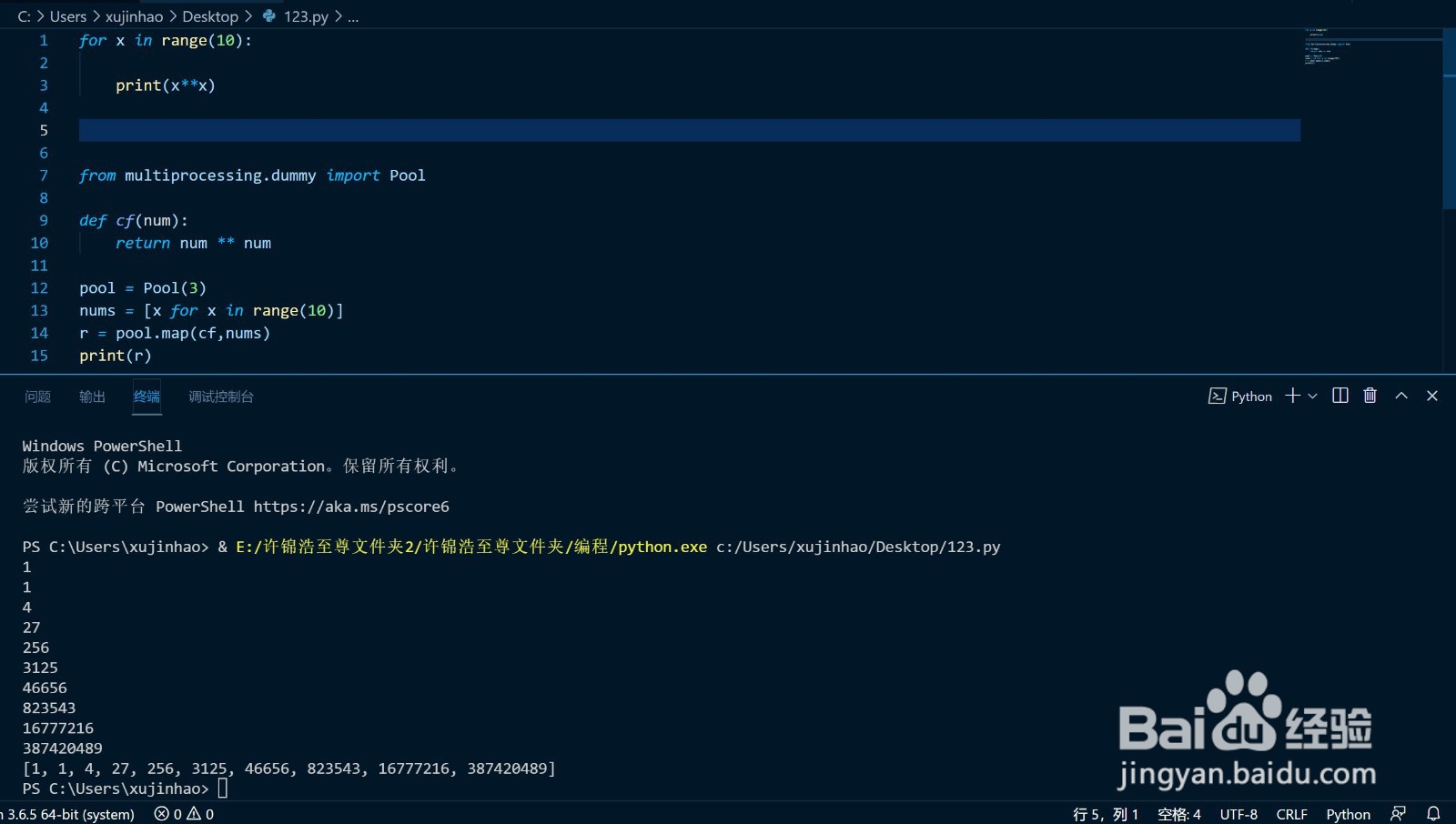
from multiprocessing.dummy import Pool
def cf(num):
return num ** num
pool = Pool(3)
nums = [x for x in range(10)]
r = pool.map(cf,nums)
print(r)
输出一个列表:[1, 1, 4, 27, 256, 3125, 46656, 823543, 16777216, 387420489]
4、上面代码中,先定义了一个函数来计算平方,然后初始化了有三个线程的线程池。multiprocessing的用法是:
pool.map(函数名,参数名)
函数名不用加括号,如
def cf(num):
return num ** num
可以写为 pool.map(cf,nums),参数必须是一个列表
5、下面开始编写爬虫访问100次百度首页,我们先导入:
from multiprocessing.dummy import Pool
定义一个爬虫函数:
def spider(nums=1):
for num in range(nums):
requests.get('https://www.baidu.com')
然后初始化线程池(这个线程池有100个线程):
pool = Pool(100)
调用函数:
pool.map(spider,[1])
把它们合起来:
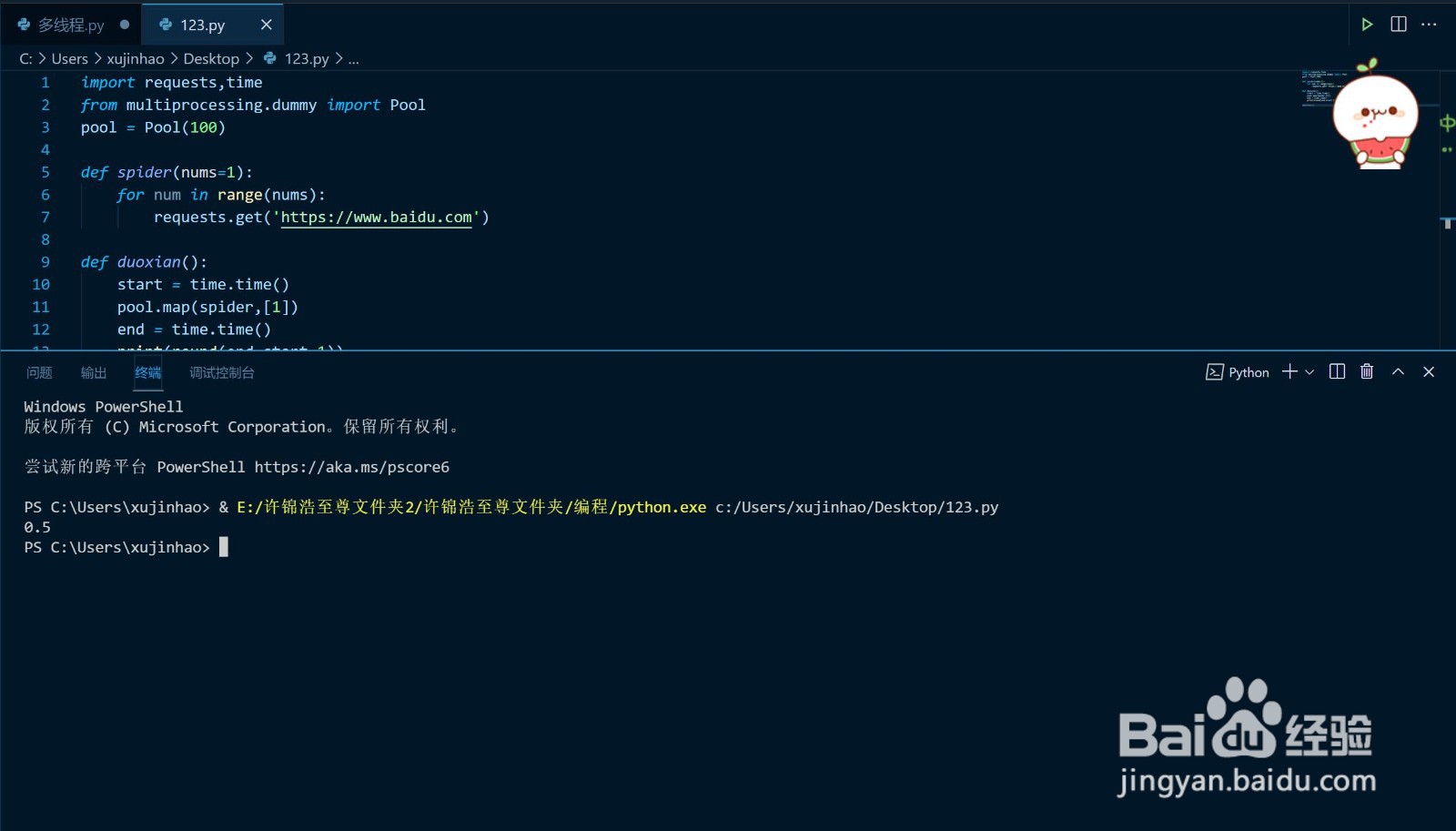
import requests,time
from multiprocessing.dummy import Pool
pool = Pool(100)
def spider(nums=1):
for num in range(nums):
requests.get('https://www.baidu.com')
def duoxian():
start = time.time()
pool.map(spider,[1])
end = time.time()
print(round(end-start,1))
duoxian()
输出:0.5
6、对比单线程的时间(12s),多线程比它快了24倍!再来试试访问1000次,多线程仅用了0.9s!而单线程用了两分钟!
7、以上就是全部内容,勿抄勿盗