rabbitmq配置集群和镜像队列
首先先安装rabbitmq,然后在继续往下看
文章标题:《rabbitmq单机安装小记》
文章地址:http://www.bbtang.info/591.html
还需要修改host文件
127.0.0.1 rabbitmq1 localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.1.254 rabbitmq1192.168.1.22 rabbitmq2
每台机子除了自己的127.0.0.1的host不同外,下边的都相同.
PS:我们使用rabbitmq1做主服务,rabbitmq2做节点服务
同时自己的机器的主机名务必要给成和你的这个是一样的,不然机器重启后,不是这个主机名,加入到集群中会出现问题的.
可以通过修改vim /etc/sysconfig/network中的HOSTNAME选项来修改,同时hostnamerabbitmq1 也是可以临时修改的.
注意要在安装完成的时候启动rabbitmq哦~
./rabbitmq-server start
说明
Rabbitmq的集群是依附于erlang的集群来工作的,所以必须先构建起erlang的集群景象。Erlang的集群中各节点是经由过程一个magic cookie来实现的,这个cookie存放在$home/.erlang.cookie中(像我的root用户安装的就是放在我的root/.erlang.cookie中),文件是400的权限。所以必须包管各节点cookie对峙一致,不然节点之间就无法通信。
复制cookie内容
打开文件然后需要先把其中的一台服务器的.erlang.cookie中的内容复制到别的机器上,最好是复制内容,因为文件权限不对的话会出现问题,在最后退出保存的时候使用wq!用!来进行强制保存即可.
普通集群
对于Queue来说,消息实体只存在于其中一个节点,A、B两个节点仅有相同的元数据,即队列结构。
当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息传输,把A中的消息实体取出并经过B发送给consumer。
所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实体。
如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,然后就没有然后了……
集群配置
主服务配置脚本
./rabbitmqctl stop_app ./rabbitmqctl reset./rabbitmqctl start_app
这个是用来在rabbitmq1上执行的,这个也可以不执行,直接在节点服务器执行下边的脚本,不过得保证这个rabbitmq服务是正常启动的.
节点服务配置脚本
./rabbitmqctl stop_app./rabbitmqctl reset./rabbitmqctl join_cluster --ram rabbit@rabbitmq1./rabbitmqctl start_app
和主服务配置脚本的唯一区别是多了第三行的内容,其中--ram指的是作为内存节点,要是想做为磁盘节点的话,就不用加--ram这个参数了,把第3行写成这样就好了
./rabbitmqctl join_cluster --ram rabbit@rabbitmq1
PS:只要在节点列表里包含了本身,它就成为一个磁盘节点。在RabbitMQ集群里,必须至少有一个磁盘节点存在。
现在先执行主节点上的脚本,等待执行完成之后再执行服务节点的脚本,顺序不要错了哦~
执行完之后分别在每台机器上查看节点状态
./rabbitmqctl cluster_status
你会分别看到如下的内容
rabbitmq1查看的集群状态结果
[root@rabbitmq1 sbin]# ./rabbitmqctl cluster_statusCluster status of node rabbit@rabbitmq1 ...[{nodes,[{disc,[rabbit@rabbitmq1]},{ram,[rabbit@rabbitmq2]}]}, {running_nodes,[rabbit@rabbitmq2,rabbit@rabbitmq1]}, {partitions,[]}]...done.
rabbitmq2查看的集群状态结果
[root@rabbitmq2 sbin]# ./rabbitmqctl cluster_statusCluster status of node rabbit@rabbitmq2 ...[{nodes,[{disc,[rabbit@rabbitmq1]},{ram,[rabbit@rabbitmq2]}]}, {running_nodes,[rabbit@rabbitmq1,rabbit@rabbitmq2]}, {partitions,[]}]...done.
两台机器的内容几乎是一样的,这样的话你的集群就建立成功了.
普通的集群模式已经建立完成了.
镜像队列
上述配置的RabbitMQ默认集群模式,但并不包管队列的高可用性,尽管互换机、绑定这些可以复制到集群里的任何一个节点,然则队列内容不会复制,固然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能守候重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,须要创建镜像队列。
镜像队列是基于普通的集群模式的,所以你还是得先配置普通集群,然后才能设置镜像队列.
我是通过网页的管理端来设置的镜像队列,也可以通过命令,官方有例子.http://www.rabbitmq.com/ha.html打开之后翻到最下边有两个例子,可以参考看看,这里只说其中的网页设置的
>1.点击admin菜单-->右侧的Policies选项-->左侧最下下边的Add / update a policy>2.按照图中的内容根据自己的需求填写>3.点击Add policy添加策略

此时你就会来你的两台rabbitmq服务器的网页管理端amind菜单下看见刚才创建的队列了.
下面我们来添加一个queues队列来看看效果,这里只是测试结果,其它的先不填写
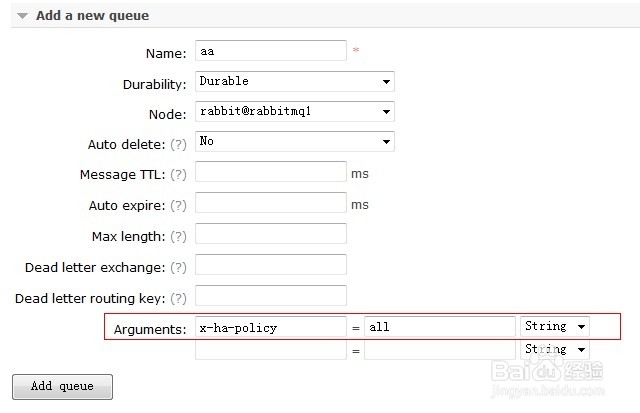
注意红框中的x-ha-policy = all这个,网上说没有这个不会进行复制,但是我测试的时候好像可以复制的,至少queues队列是可以的,先添上吧.
在这里边添加的时候你是可以指定Node选项也就是把这个queues放在哪个node节点上,不过做镜像的时候就没有必要了,呵呵
添加完成后你会看到这个效果
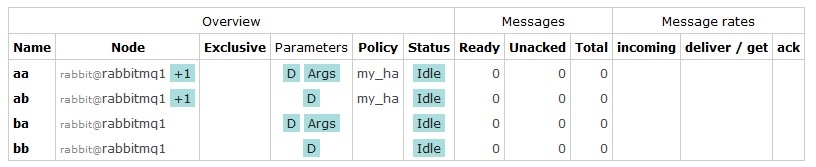
简要说明一下
aa这个是刚才添加的Arguments 参数指定了x-ha-policy = all
ab这个是没有指定Arguments参数的,这个可以看出差距的
ba和bb是为了做演示效果对比的,这两个是没有符合同步策略的,所以Node后边没有+1的标识,你把鼠标放在+1的标识上就能看到他在另一台机器上也有一个.
Q:你说要是我重启rabbitmq2的话会出现什么效果....
A:aa和ab的+1标识消失,启动后重新恢复.
Q:要是重启rabbitmq1的话出现什么效果....
A:在rabbitmq2上aa和ab的+1标识消失且Node选项中的rabbit@rabbitmq1变成rabbit@rabbitmq2,同时ba和bb消失,重启后依旧消失,哈哈,因为这两个没做镜像哦~
这里的镜像队列的集群介绍就到这里,要想做到高可用,需要HA软件的配合哦~ 这里先不做赘述,下篇文章再说吧....
报错处理
要是错误信息中提示有主节点冲突的话,可以进入到一下目录修改相应的文件
cd /usr/local/rabbitmq_server-3.1.3/var/lib/rabbitmq/mnesiavim rabbit\@rabbitmq2/cluster_nodes.config
或者直接将这个目录里的文件全都删除,这个是集群的配置文件和持久化的数据存储位置,能改则改实在是迫不得已再删除