关于在pycharm上scrapy创建爬虫项目的两种方式
1、第一步先打开软件
2、第二部点击创建项目
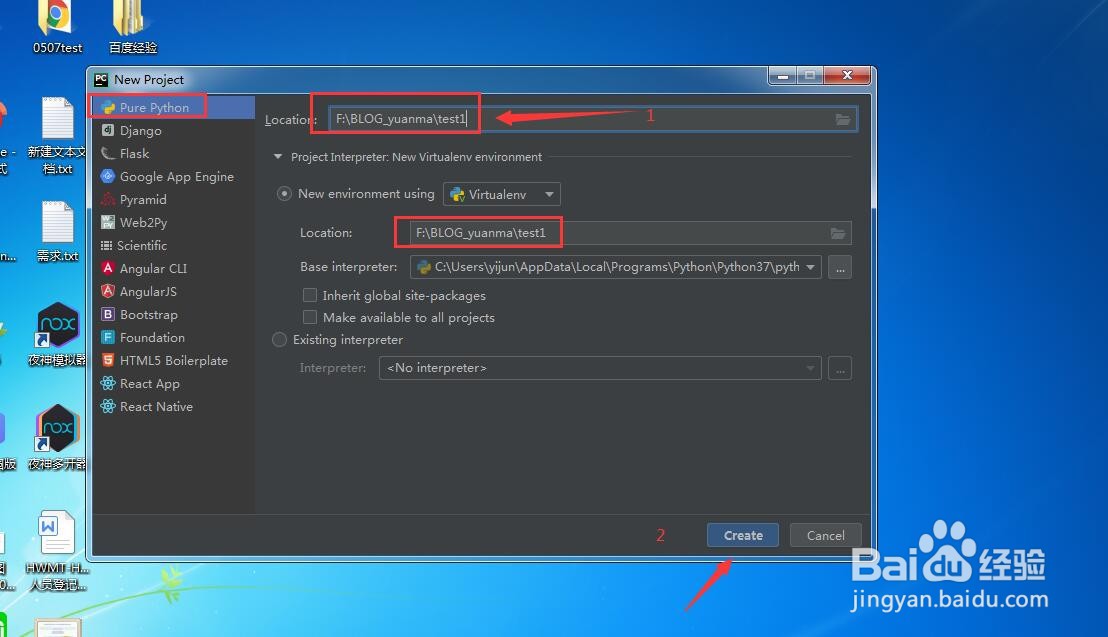
3、第三步确定项目的地址,图中的中间的红框,意思是指该项目的虚拟环境的位置,这个基本上不用管,点击create 创建项目
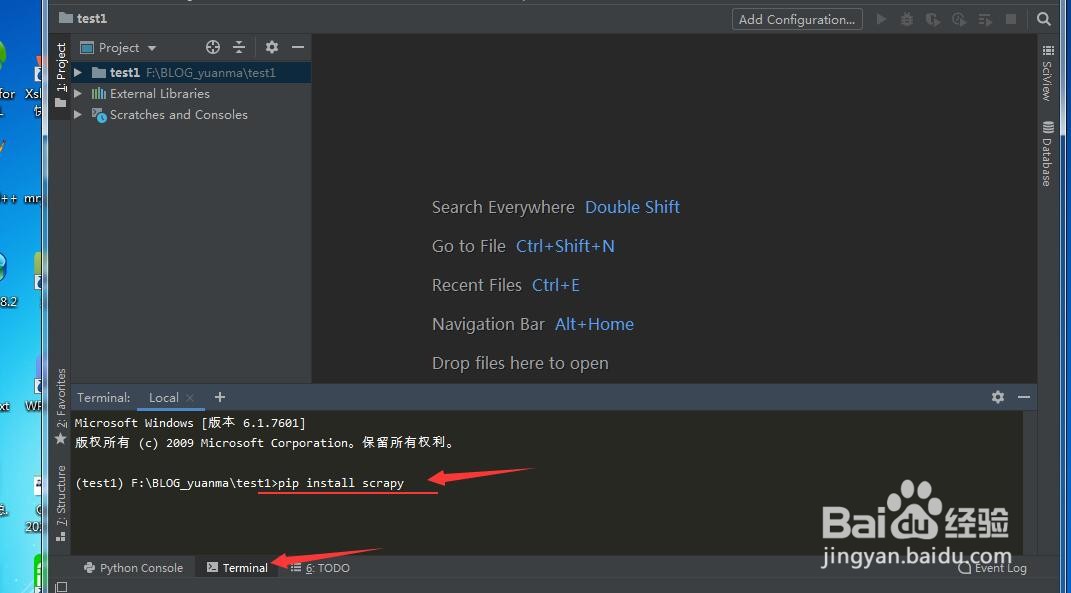
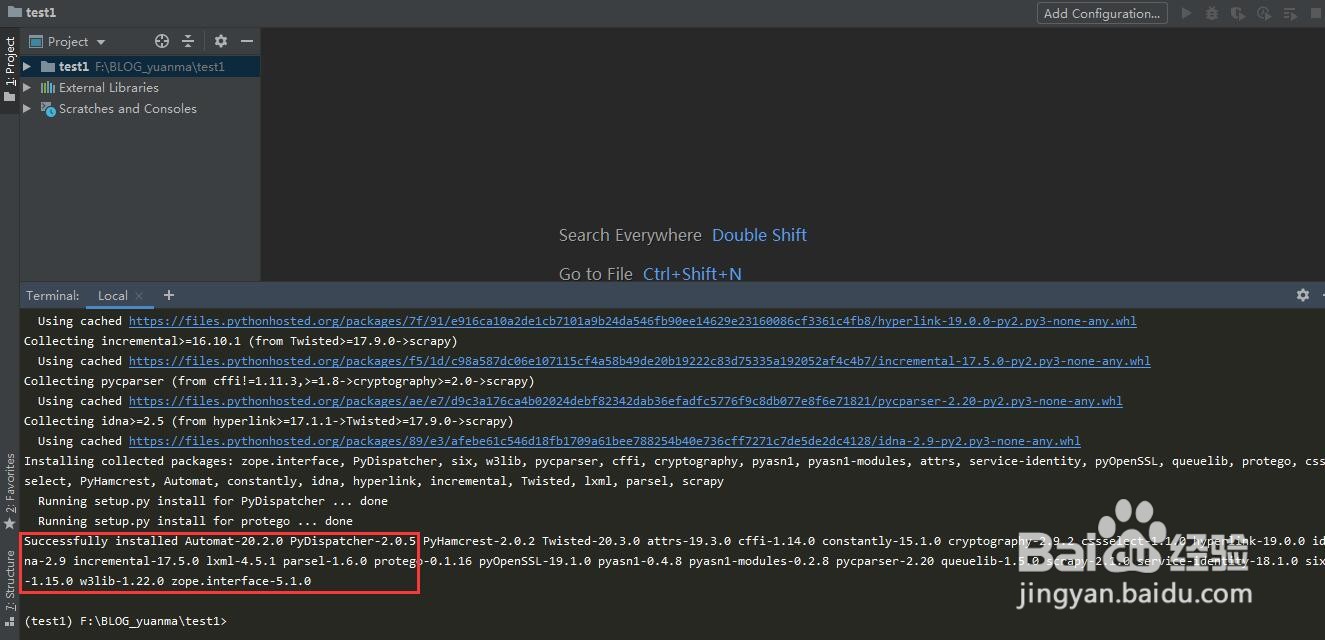
4、在项目创建完成后,会看下入下图界面,左边是我们的项目名称,看到下面,有一个terminal 我们点击它,并输入pip install scrapy, 表示开始安装scrapy软件,成功安装完成后如图所示
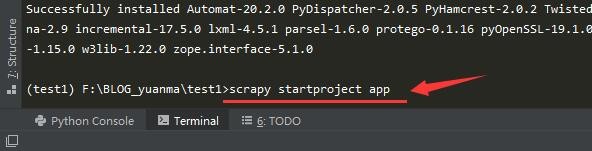
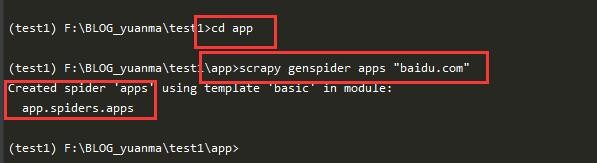
5、接下来我们输入 scrapy startproject app, 这里app我们要创建的爬虫的文件夹,可以随意,但是前面的是固定飙空蒈开格式,然后我们cd app,进入到爬虫的文件夹,输入 scrapy genspider apps “baidu.com”,这里apps代表我们这个爬虫文件的名字,爬虫代码主要业务逻辑是在这个文件下实现的,后面的引号内,代表,目标网站的域名,前面的是固定格式
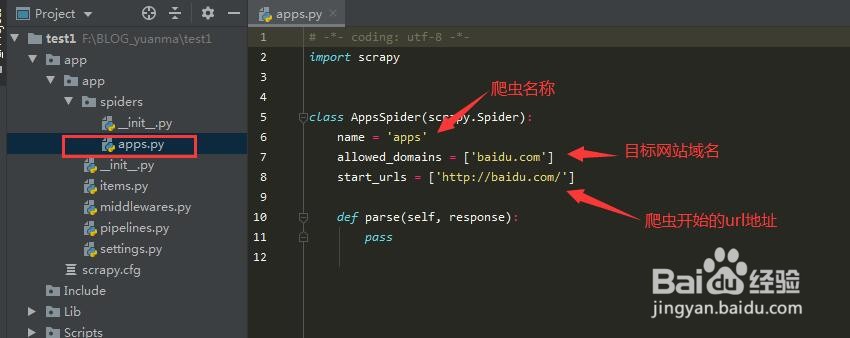
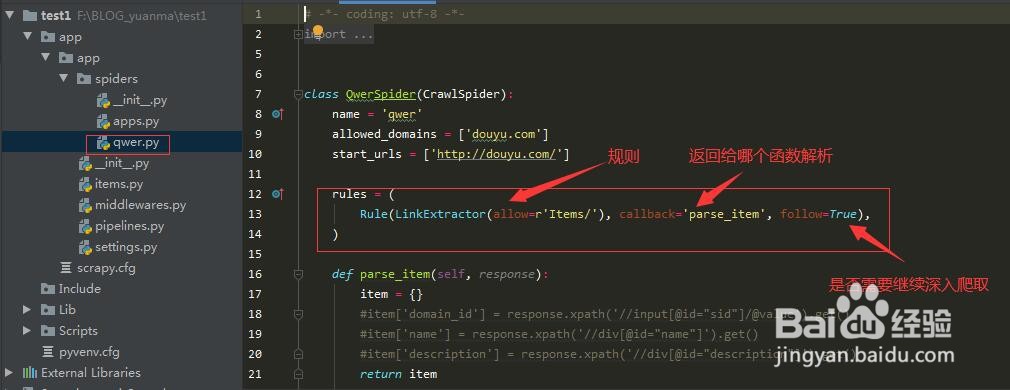
6、还有另外一种爬虫文竭惮蚕斗件的创建方式,如下图所示,还是在之前的那个文件夹下,qwer是我们这个爬虫文件的名称,后面引号内是目标网站的域名,创建完成之后我们打开它,是不是和之前不一样吧,同样都是爬虫文件,第二种的功能就多一点,allow内部代表符合某种规则的url地址,它都会去爬去,并且由callback指向的函数来解析它,最后的follow意思为是否还需要深度爬取,值只有true和false两个,大家有没有get到呢