CentOS7安装配置Hadoop2.7.3
1、准备Linux环境
查看本地主机名:hostname
更改主机名:hostname 新名
如:hostname localhost
2、关闭防火墙
#1、关闭防火墙:
#1、关闭防火墙:
sudo systemctl stop firewalld.service
#2、关闭开机启动:
sudo systemctl disable firewalld.service
3、安装JDK和Hadoop
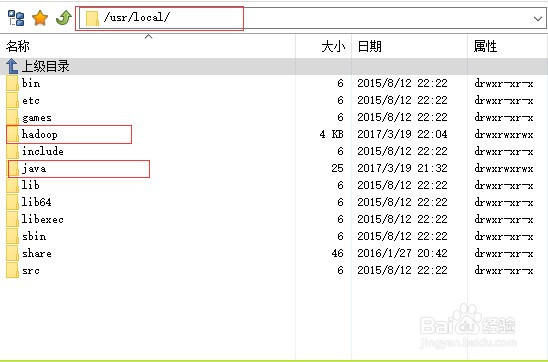
1、在/usr/local/目录下创建两个文件夹hadoop/java,里面用于存放jdk和hadoop解压文件(结构如图所示)2、解压(可以用FlashFXP解压好上传)
解压指令:
tar -xzvf file.tar.gz
1、将JDK和hadoop添加到环境变量(重要):
2、打开:vim /etc/profile
注意:如果没装vim可以安装一下(指令:# yum -y install vim*)
export JAVA_HOME=/usr/local/java/2、掌握在单机上运行Hadoop的方法。
export HADOOP_HOME=/usr/local/hadoop/
export JAVA_BIN=$JAVA_HOME/bin
export JAVA_LIB=$JAVA_HOME/lib
export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
///////////////////////////////////分割线//////////////////////////////
保存完后记得执行指令是之生效
source /etc/profile
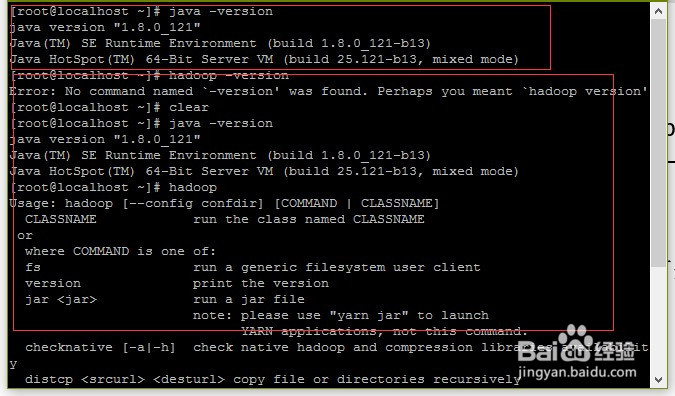
3、检查环境变量是否正确
输入指令:JAVAC
hadoop
显示结果如下:
1、集群、单节点模式都需要用到 SSH免密 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上面运行命令)所以需要配置SSH
2、#安装vim
yum -y install vim*
# 安装openssh-server
yum install -y openssl openssh-server
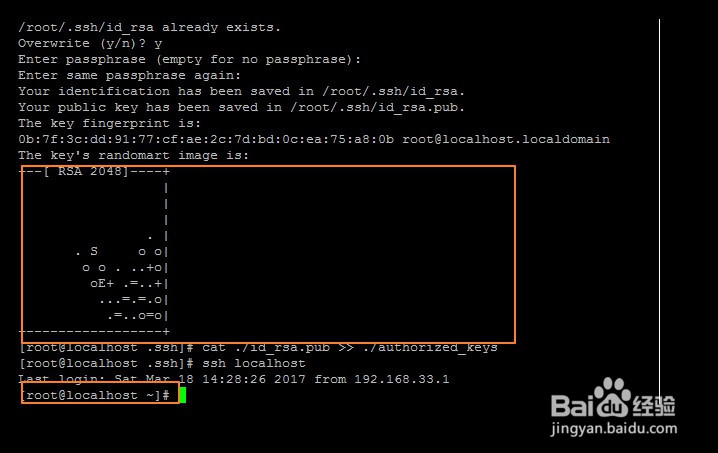
ssh localhost
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
3、到此单机模式hadoop已经配置完毕!!!
1、修改:core-site.xml
vim ./etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2、修改:hdfs-site.xml
vim ./etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
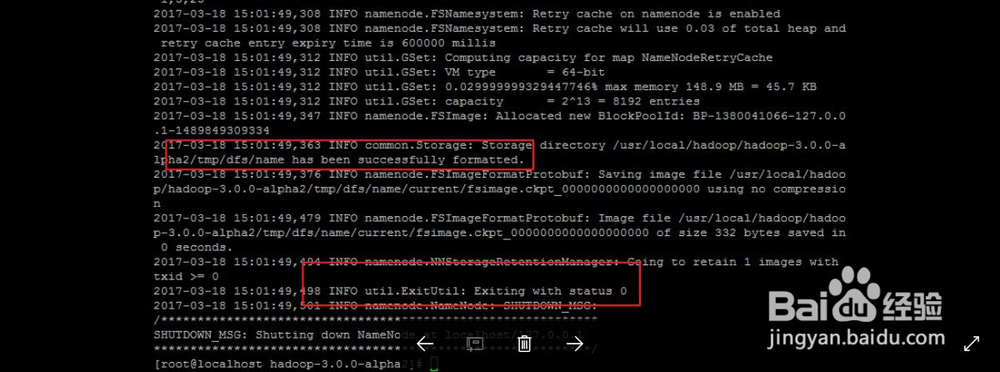
3、#配置完成后,执行 NameNode 的格式化:
./bin/hdfs namenode -format
#接着开启 NameNode 和 DataNode 守护进程。
./sbin/start-dfs.sh
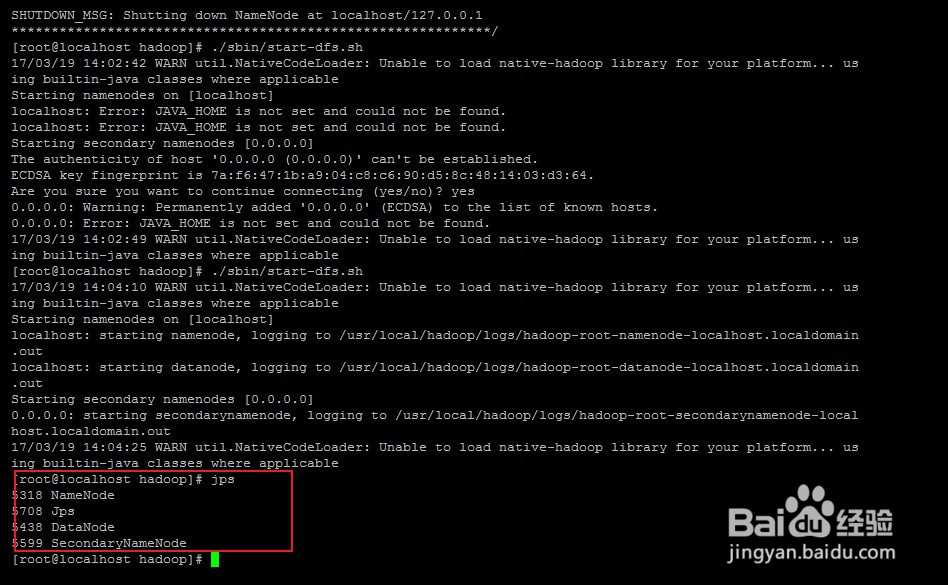
1、新建两个文件(1.text、2.text)
1.txt //输入的是hello hadoop
2.txt //这里输入的是hello hadoop hello mapreduce
2、#运行Hadoop自带wordcount程序
./bin/hdfs dfs -mkdir -p /user/hadoop //在hdfs上创建文件目录
./bin/hdfs dfs -mkdir /input //创建文件夹input作为HDFS的输入文件夹
./bin/hdfs dfs -put /usr/local/hadoop/input/*.txt /input //将本地文件上传到hdfs
(可以使用./bin/hdfs dfs -ls /input查看input里的文件)
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha2.jar wordcount input output //运行自带的wordcount程序
./bin/hdfs dfs -cat output /*
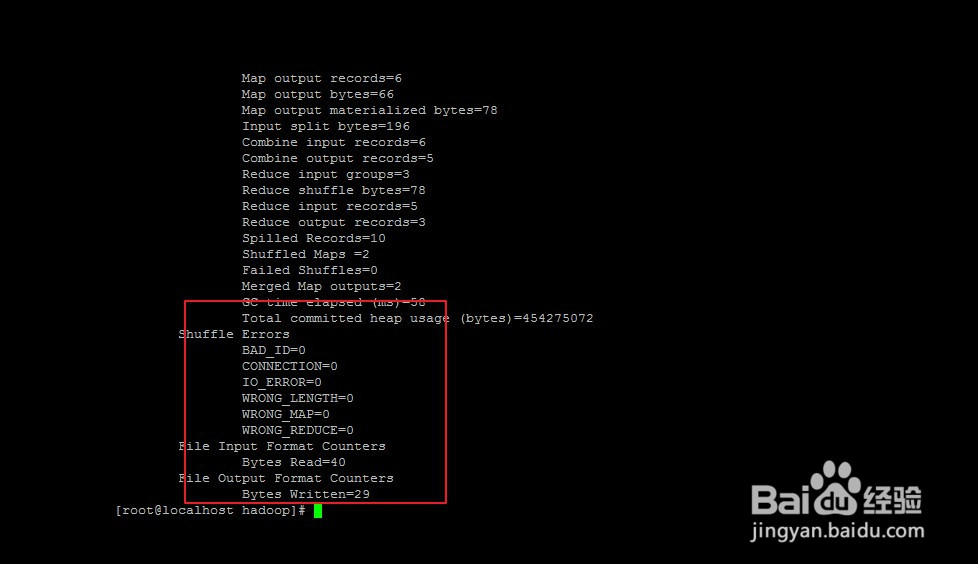

3、到此,Hadoop伪分布式配置完毕!