如何识别PDF扫描件中的文字
1、打开360搜索,如图。

2、输入“汉王ocr文字识别软件”,点击搜索。

3、选择第一个下载地址,点击进入。

4、点击下方的“立即下载”。

5、下载完成后,在文件夹中点击图标即可打开软件。
6、点击文件,选择下方的"打开图像"。

7、找到想要提取文字的PDF文档,点击下方的“打开”。

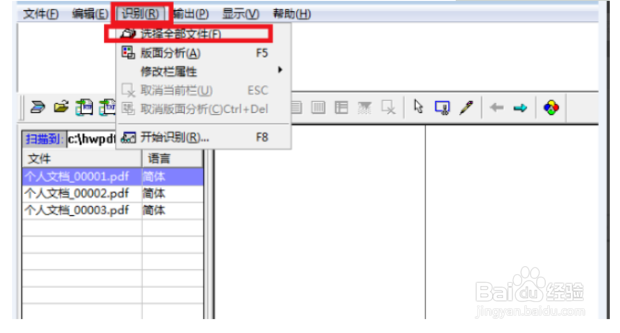
8、在工具栏中选择识别,再点击“选择全部文档”。
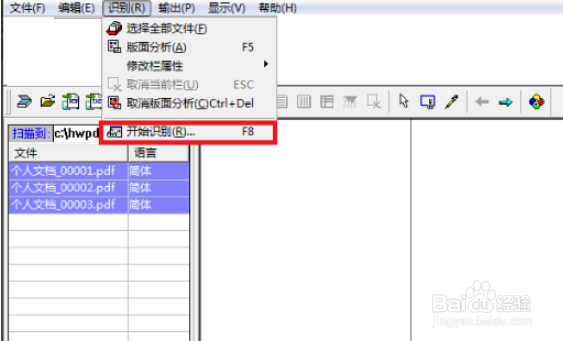
9、再点击最下方的“开始识别”。
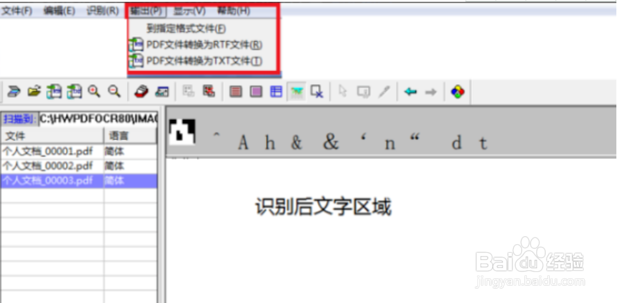
10、在上方就可以看到被识别的文字。

11、转换完成后,通过菜单栏选择需要的格式进行保存即可。
阅读量:105
阅读量:44
阅读量:190
阅读量:127
阅读量:100