scrapy框架解读
1、 如图中所示的article_zhihu就是使用scrapy startproject XXX 命令生成的项目文件
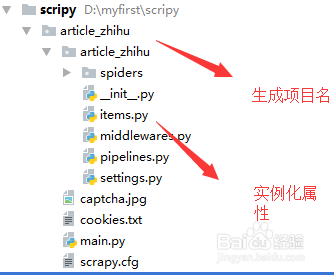
2、 之后使用scrapy genspider XXX XXXX则是生成了图片中的划线文件,并默认产生爬虫的名称和链接地址,XXX 作为爬虫名,XXXX作为链接地址。


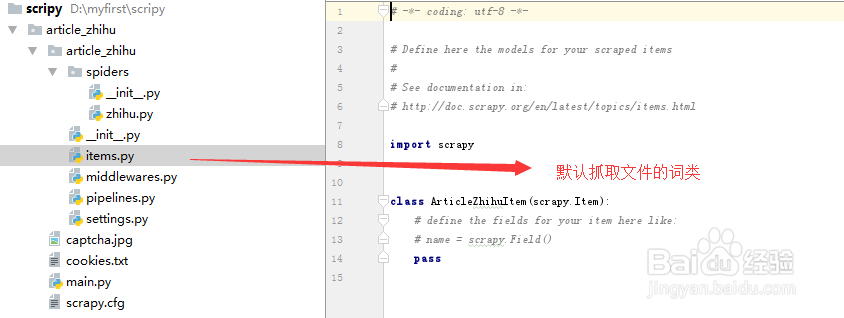
3、 items.py是用于存放页面爬取的词类,如标题,发布时间,链接地址等。存放之后可以用于进行数据处理
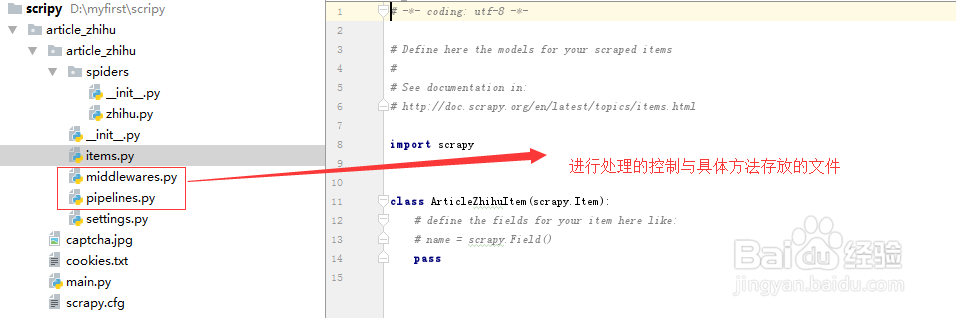
4、 middlewares.py和pipelines.py主要存放的是对爬取后数据进行处理的方法与控制的方法。
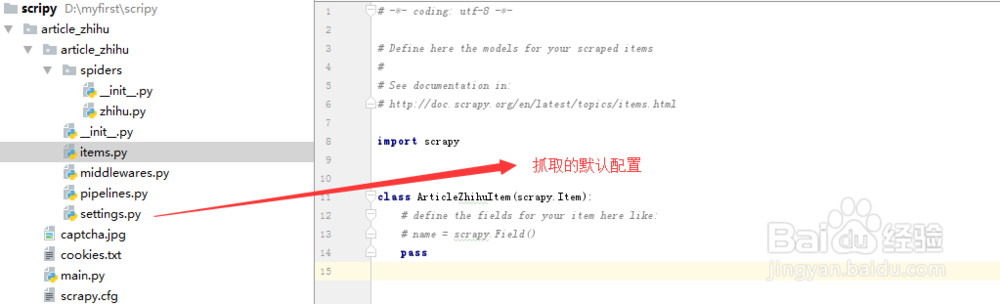
5、 settings.py内的文件是scrapy程序的具体配置,每一个scrapy都会因为自己爬取不同而与不同的配置。
阅读量:23
阅读量:20
阅读量:27
阅读量:160
阅读量:76