如何批量处理重复数据的通用办法(无视版本)
1、今天接前几天继续,向提议矣把噌供新数据的那货指出问题后,开始批量处理重复数据,虽然截图中是连续且少量数据,我们就想象成有1000条且没有紧挨在一起,藏匿于大数据中。我们现在要设法找到他们

2、首先使用筛选功能,快捷键“ALT+A+T”,然后将H列的内容为“#REF!”的筛选保留,其他数据的“√”去掉
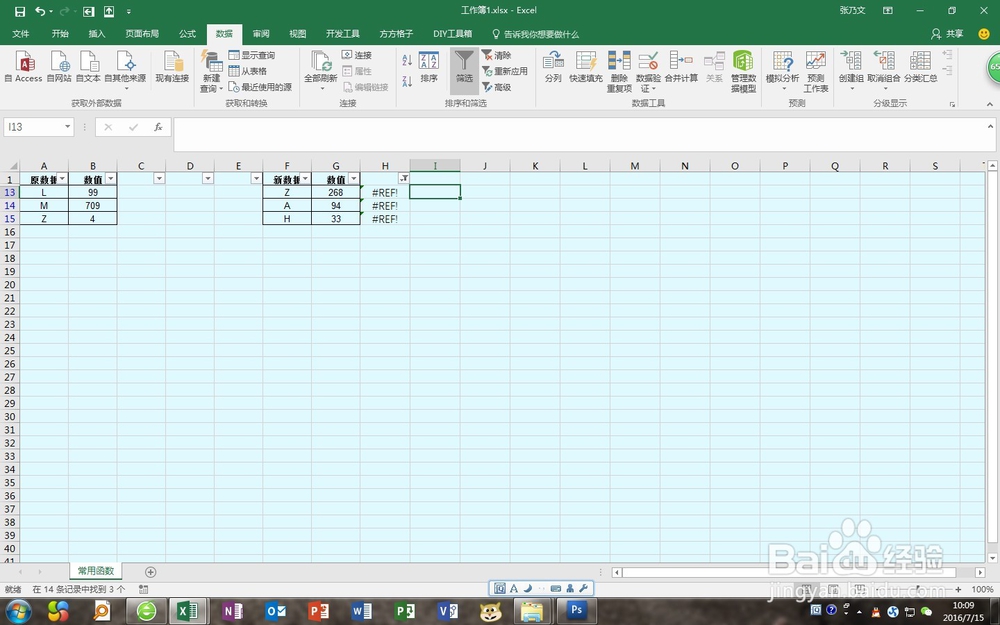
3、在其后面的“I”列,键入内容“1”。内容这个随你爱好,没有要求,就是输入个数据便于后面查找
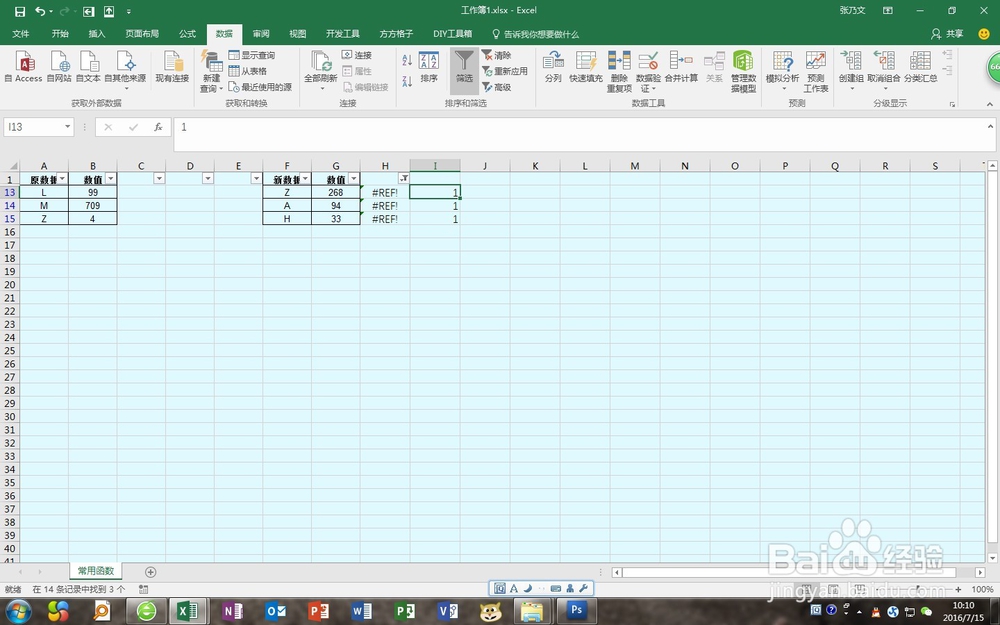
4、再使用一次快捷键“ALT+A+T”,作用是为了取消筛选。当然你爱用鼠标控制就把“H”列的小三角点一下,把里边内容全选就是了
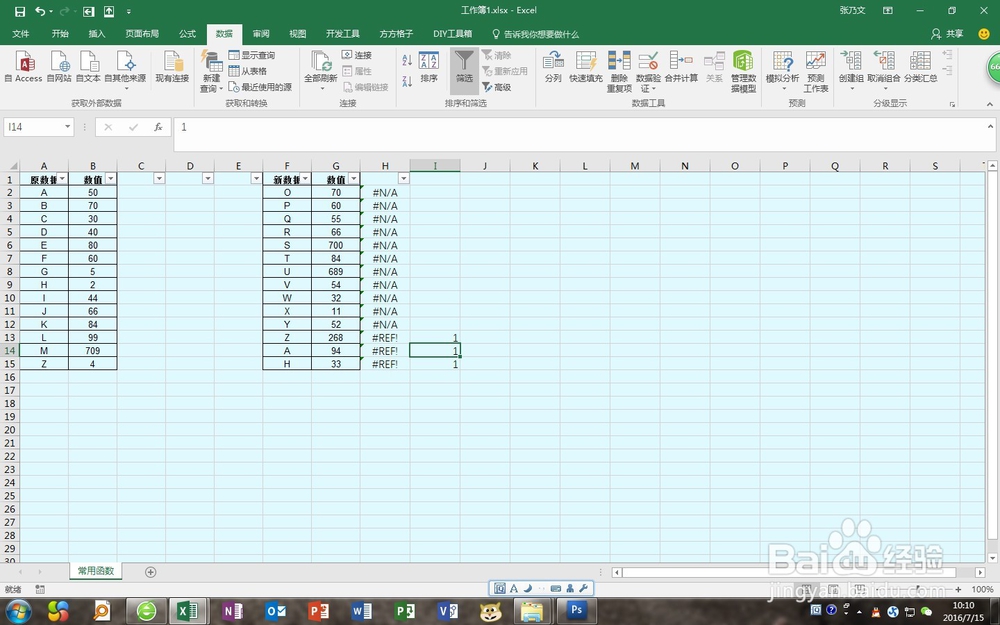
5、再使用一次快捷键“ALT+A+T”,作用是为了将“I”列也加入筛选。然后使用升序排列,这时候,之前键入的内容,不管在表格中的哪一行,都后跑到表格的最上面
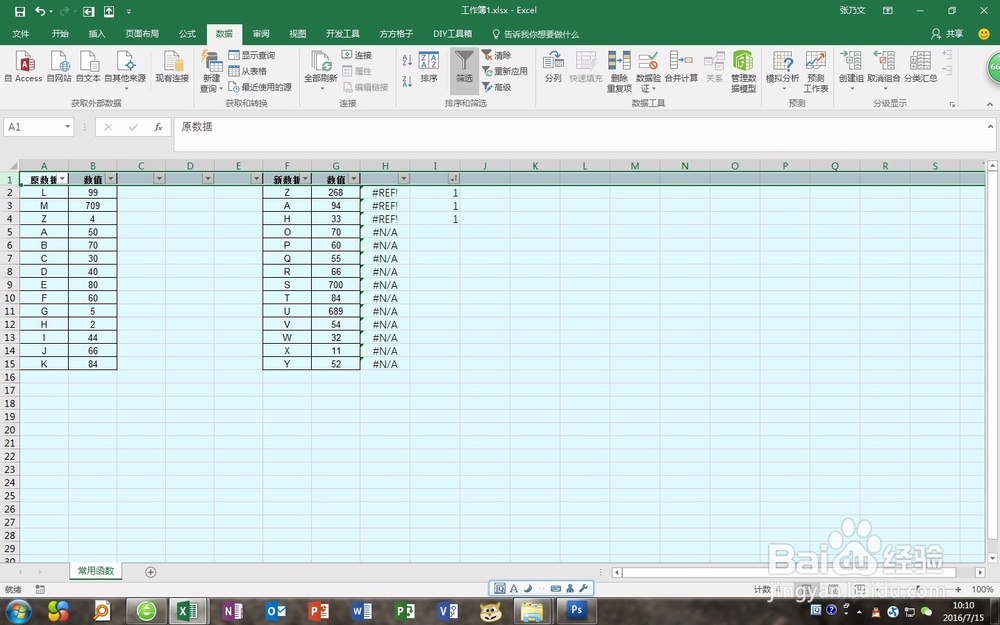
6、这个时候在将这些内容丸泸尺鸢框选再删除。也许有人会问,为什么不在第二步筛选出结果的时候直接删除?我想说,兄弟你是用2013版以上的吧!你敢不敢用2003-07版的这么操作一下
7、这时候就可以把数据合并到一列去了
