Python用Scrapy框架编写一个属于自己的爬虫
1、在cmd中使用scrapy startproject tutorial命令创建出Scrapy模版

2、这个siders文件加里就是用来放蜘蛛的,哈哈,人如其名,只用用的框架环境都是一样的只要编写不同内容的蜘蛛放到这里面就行了
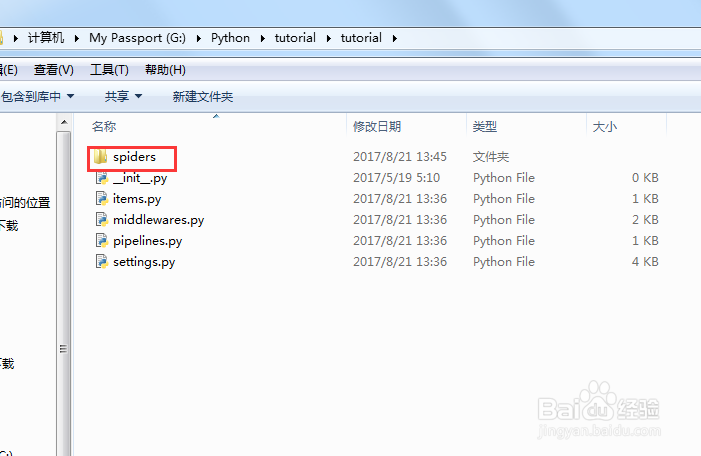

3、如何,创建一个python文件,.py,这就是一只刚出生的小蜘蛛了,接下来我们为这只蜘蛛编写智商
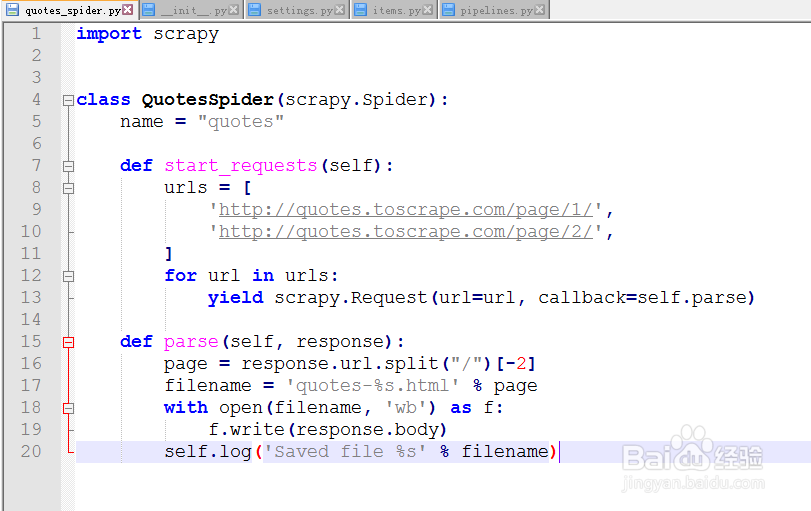
4、import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/'
'http://quotes.toscrape.com/page/2/'
]
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename,'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
写入这些内容,这是python代码,写爬虫,起码python基本语法得能看懂

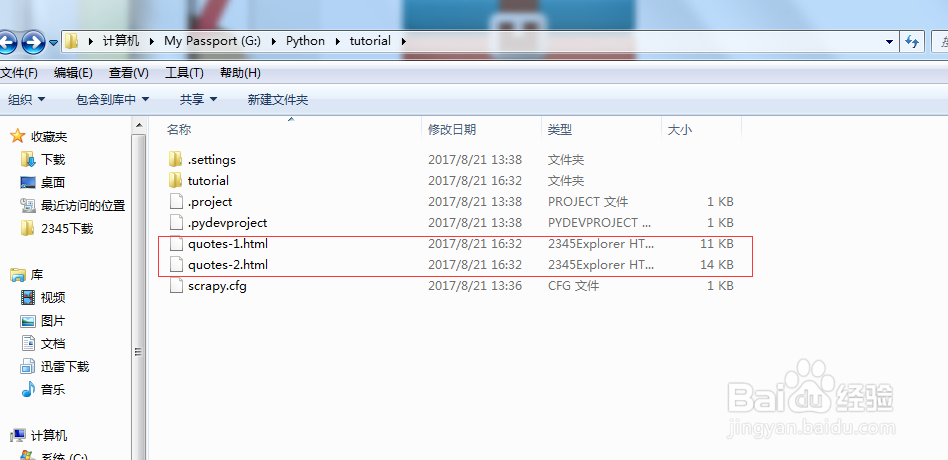
5、在顶层目录G:\Python\tutorial 执行cmd命令 scrapy crawl quotes 得到如下结果

6、这个时候网页已经被爬取下来,保存在当前文件夹的目录里了
7、不过细心的你肯定会发现,保存下来的网页打开来和在浏览器里直接访问的是不太一样的,这是由于Scrapy不支持js渲染,有一部分内容格式是要有js动态渲染生成的,这个可以在后期家装插件,使得Scray支持js渲染

8、恭喜,大功告成,第一个范例爬虫编写完毕!!!
