LeadTools创建“识别图像中的中文”应用的步骤
1、下面为您提供了”使用OCR识别图像中的中文“的示例代码。为了运行此代码,您需要下载LeadTools全功能试用版。
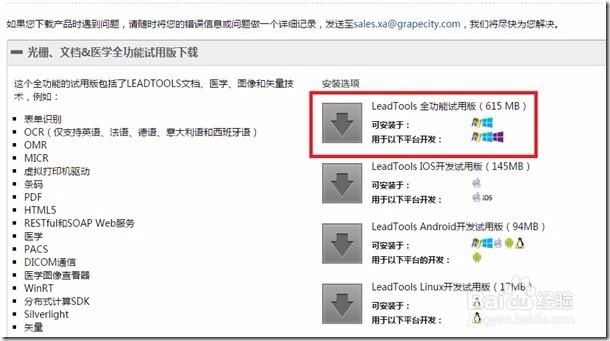
2、安装全功能试用版后,由于此应用程序要识别中文,因此在创建应用程序之前,您还需要下载安装LeadTools OCR语言扩展包。
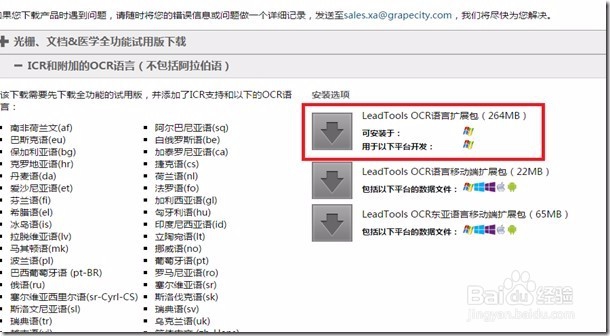
3、安装完OCR语言扩展包,我们就可以开始创建“使用OCR识别中文”的应用程序了,我们将最终的识别结果保存为.docx格式。
1、打开Visual Studio .NET。点击 文件->新建->项目…。打开新建项目对话框后,在模板中选择“Visual C#”,随后选择“Windows窗体应用程序”。在名称栏中输入项目名称“SampleOcrChinese”,并使用“浏览”按钮选择您工程的存储路径,点击“确定”。
2、在“解决方案资源管理器”中,右击“引用”,选择“添加引用”。根据当前工程的 Framework 版本和生成目标平台,选择添加相应的LeadTools控件,例如工程中的版本为 Framework 4.0、生成目标平台是 x86,则浏览选择Leadtools For .NET文件夹”<LEADTOOLS_INSTALLDIR>\Bin\DotNet4\Win32”,选择以下的DLL“:
Leadtools.dll
Leadtools.Codecs.dll
Leadtools.Codecs.Bmp.dll
Leadtools.Codecs.Cmp.dll
Leadtools.Codecs.Fax.dll
Leadtools.Codecs.Tif.dll
Leadtools.Forms.dll
Leadtools.Forms.DocumentWriters.dll
Leadtools.Forms.Ocr.dll
Leadtools.Forms.Ocr.Professional.dll
Leadtools.WinForms.dll
点击“确定”按钮,将以上所有的DLL添加到应用程序中。
注意:添加Leadtools.Codecs.*.dll引用后,可使用BMP、JPG、CMP、TIF和FAX图像文件格式。如果您想使用更多的文件格式,可添加相关文件格式的codec DLL至应用程序。
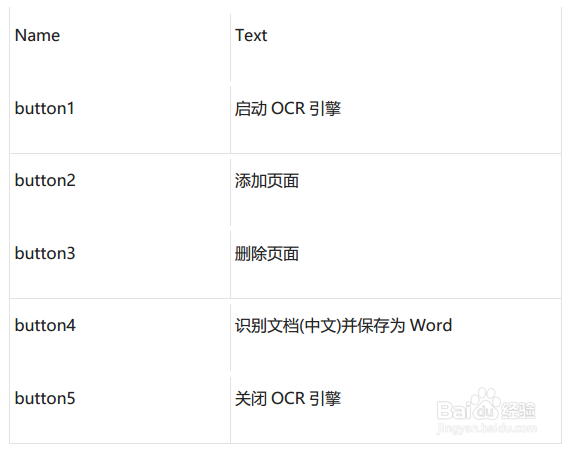
3、拖拽5个button控件至Form1。Button的名称默认为“button1,button2…”,根据以下表格修改相应的Text属性:
4、将Form1切换至代码视图,将以下代码添加至using 部分:
1: using Leadtools;
2: using Leadtools.Codecs;
3: using Leadtools.Forms;
4: using Leadtools.Forms.DocumentWriters;
5: using Leadtools.Forms.Ocr;
6: using Leadtools.ImageProcessing;
7: using Leadtools.WinForms;
5、将以下私有变量添加至Form1类:
1: private IOcrEngine _ocrEngine;
2: private IOcrDocument _ocrDocument;
6、将以下代码添加至Form1的构造函数:
1: InitializeComponent();
2: // 解锁OCR功能,用您的密钥替换此处
3: string MY_LICENSE_FILE = "d:\\temp\\TestLic.lic";
4: string MY_DEVELOPER_KEY = "xyz123abc";
5: RasterSupport.SetLicense(MY_LICENSE_FILE, MY_DEVELOPER_KEY);
6: // 初始化OCR引擎
7: _ocrEngine = OcrEngineManager.CreateEngine(OcrEngineType.Professional, false);
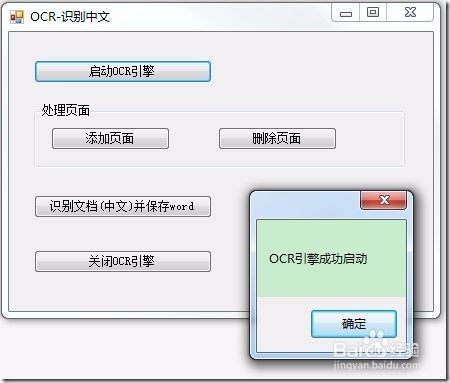
7、将以下代码添加至button1(启动OCR引擎)按钮的Click句柄中,启动OCR引擎,在此部分将识别的语言设置为中文简体:
1: // 启动OCR引擎
2: _ocrEngine.Startup(null, null, null, @"D:\LEADTOOLS 18\Bin\Common\OcrProfessionalRuntime");
3: // 创建文档
4: _ocrDocument = _ocrEngine.DocumentManager.CreateDocument();
5: //将语言设置为中文简体,中文繁体为"zh-Hant"
6: _ocrEngine.LanguageManager.EnableLanguages(new string[] {"zh-Hans"});
7: MessageBox.Show("OCR引擎成功启动");
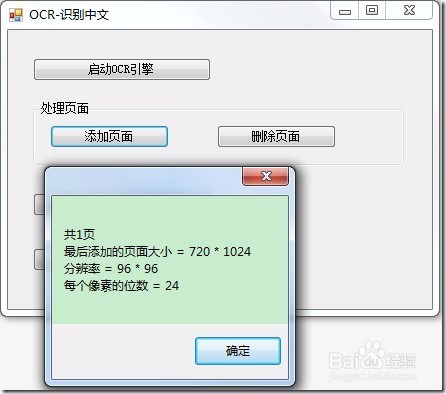
8、将以下代码添加至button2(添加页面)的Click句柄中,将单页图像文件添加至OCR文档:
1: string fileName = Path.Combine(Application.StartupPath, @"..\..\Pic\chineseImage.bmp");
2:
3: //将包含中文字符的文件添加至OCR文档
4: IOcrPage page = _ocrDocument.Pages.AddPage(fileName, null);
5: int pageCount = _ocrDocument.Pages.Count;
6: // // 显示此页面的相关信息
7: string message = string.Format(
8: "共{0}页\n最后添加的页面大小 = {1} * {2}\n分辨率 = {3} * {4}\n每个像素的位数 = {5}\n",
9: pageCount,
10: page.Width, page.Height,
11: page.DpiX, page.DpiY,
12: page.BitsPerPixel);
13: MessageBox.Show(message);
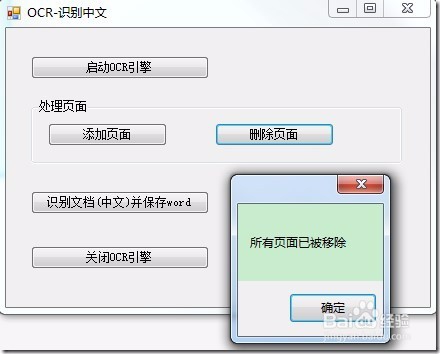
9、将以下代码添加至button3(删除页面)的Click句柄,从OCR文档中移走了所有页面:
1: // 从OCR文档中移除所有添加的页面
2: _ocrDocument.Pages.Clear();
3: MessageBox.Show("所有页面已被移除");
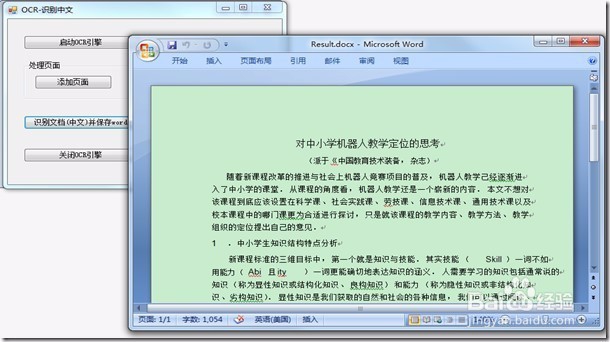
10、将以下代码添加至button4(识别文档(中文)并保存为Word)的Click句柄,识别文档中的中文字符,并将识别的结果保存为Word文档:
1: // 识别所有页面
2: // 注意,我们不需要调用AutoZone,引擎会检查页面是否被分区,若无,则会自动分区
3: _ocrDocument.Pages.Recognize(null);
4: // 将结果保存为Word文档
5: string wordFileName = Path.Combine(Application.StartupPath, @"..\..\Result\Result.docx");
6: _ocrDocument.Save(wordFileName, DocumentFormat.Docx, null);
7: // 显示我们刚刚保存的word文件
8: System.Diagnostics.Process.Start(wordFileName);
11、将以下代码添加至button5(关闭OCR引擎)按钮的Click句柄,关闭OCR引擎:
1: // 释放此文档
2: _ocrDocument.Dispose();
3: // 关闭OCR引擎
4: _ocrEngine.Shutdown();
5: MessageBox.Show("OCR引擎关闭");
此段代码会将最终的识别结果保存为PDF文件。可按照依照以下步骤:启动OCR引擎->添加页面->识别文档(中文)并保存为Word->删除页面->关闭OCR引擎。
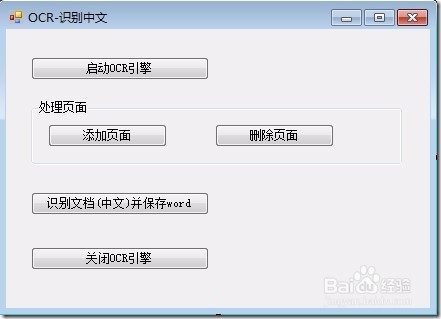
12、编译、运行程序。结果如下图:
原图像为:

13、运行程序识别过程的截图如下: