python 3 如何获取pdf中的文字
1、首先,使用命令pip install pdfminer安装pdfminer(注意pip要是python3的,如果系统中还有python2,建议创建venv环境再用python和pip)。

2、安装好之后,对于linux用户,即可直接输入pdf2txt.py回车运行。
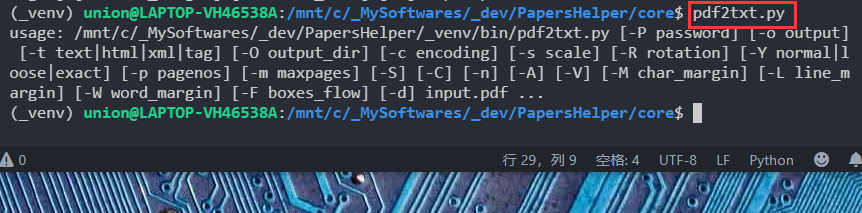
3、如图命令将test.pdf文件的文字抽取并输出到test.txt文件中。

4、如果要获取pdfminer更详细的使用说明,可以找到github上的euske/pdfminer仓库。
5、我们也可以直接查看pdf2txt.py的代码,观察其实现方式。

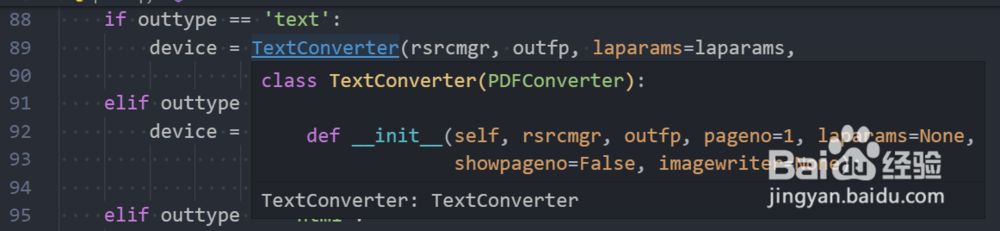
6、找到其中处理文本输出的部分,如图所示,结合前后即可提取文本输出的代码。
7、最终提取出来的代码如图所示,pdf_gettext即根据文件名,获取文件,并打印到stdout。

1、首先,使用命令pip install pdfminer安装pdfminer(注意pip要是python3的,如果系统中还有python2,建议创建venv环境再用python和pip)。
2、安装好之后,对于linux用户,即可直接输入pdf2txt.py回车运行。
3、如图命令将test.pdf文件的文字抽取并输出到test.txt文件中。
4、如果要获取pdfminer更详细的使用说明,可以找到github上的euske/pdfminer仓库。
5、我们也可以直接查看pdf2txt.py的代码,观察其实现方式。
6、找到其中处理文本输出的部分,如图所示,结合前后即可提取文本输出的代码。
7、最终提取出来的代码如图所示,pdf_gettext即根据文件名,获取文件,并打印到stdout。
阅读量:162
阅读量:28
阅读量:101
阅读量:27
阅读量:134