Python正则表达式如何非贪婪模式匹配
1、打开Python开发工具IDLE,点击File -- New file ,新建‘testPP.py’文件。
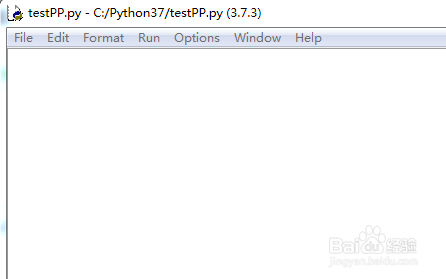
2、在‘testPP.py’文件中编写代码如下:
import re
sss = '<aaa><bbb><ccc>'
ret = re.findall('<.*>',sss)
print (ret)
默认模式,正则表达式是贪婪匹配,从'<'符号开始匹配到最后的'>'符号。
. 代表任意字符,除\n外
* 代表前一个字符0次或者无限次
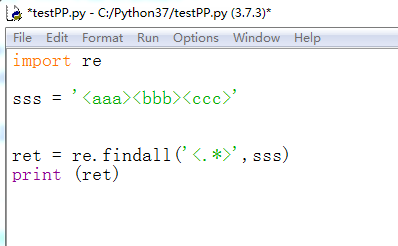
3、F5运行代码,效果如下图所示,匹配到的内容为['<aaa><bbb><ccc>']。

4、但是如果需要区分开每个尖括号的内容,就要使用正则表达式的非贪婪模式,代码如下:
import re
sss = '<aaa><bbb><ccc>'
ret = re.findall('<.*?>',sss)
print (ret)
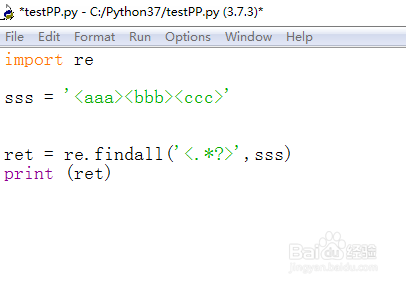
5、F5运行代码,效果如下图所示,匹配到的内容为['<aaa>', '<bbb>', '<ccc>'],成功的把每个尖括号分离了。

6、当有\n换行符,比较麻烦,代码如下:
import re
sss = '''<aaa>
<bbb>
<ccc>'''
ret = re.findall('<.*>',sss)
print (ret)
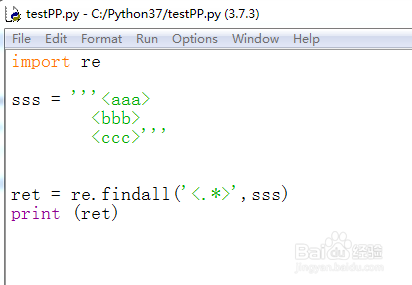
7、F5运行代码,在不加问号时即贪婪模式也能单独匹配了,但是这是因为'.'无法匹配换行符,

8、修改代码,实现多行匹配使用re.S模式,代码如下:
import re
sss = '''<aaa>
<bbb>
<ccc>'''
ret = re.findall('<.*>',sss,re.S)
print (ret)
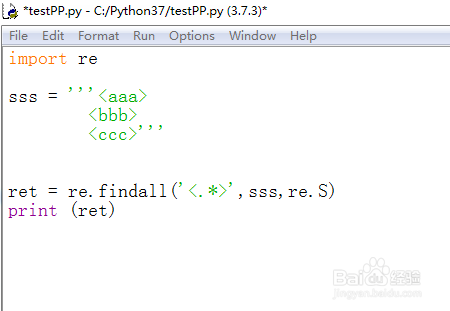
9、F5运行代码,效果如下图,这次是真正匹配到包含\n的内容,因为这是贪婪模式匹配的。
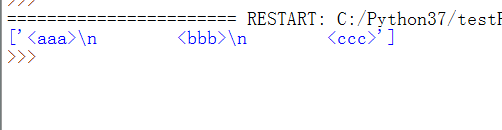
10、要想实现第5步的效果,使用非贪婪模式,修改代码如下:
import re
sss = '''<aaa>
<bbb>
<ccc>'''
ret = re.findall('<.*?>',sss,re.S)
print (ret)
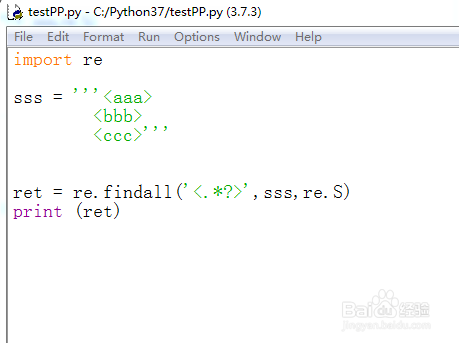
11、F5运行代码,效果如下图所示,达到了非贪婪匹配的目的。
