python实现url编码后抓取网页源码
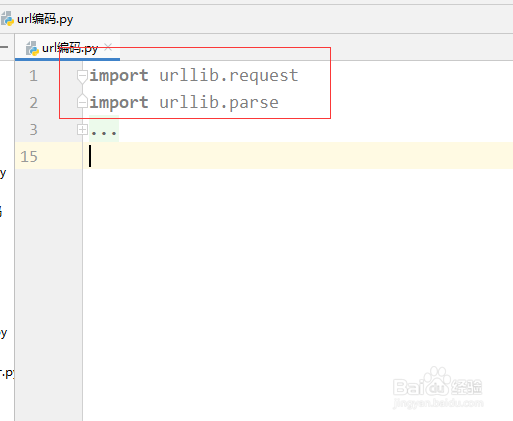
1、用import 代码导入相关模块,我们用到urllib模块中的两个功能,具体如下:
import urllib.request
import urllib.parse
其中request 是用来发送请求,parse 是用来进行编码转换
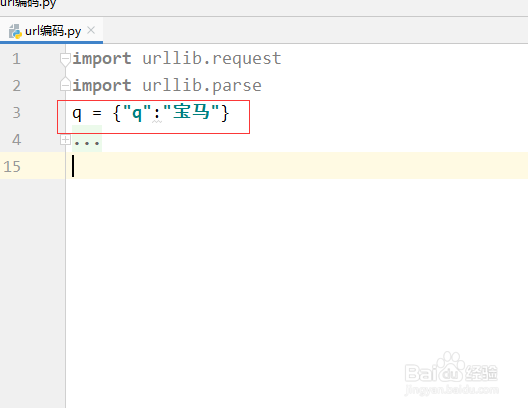
2、这里我用某汽车网站为例进行说明。
建立一个字典,具体代码为:q = {"q":"宝马"}
其中key值设置为q ,value 设置为“宝马”
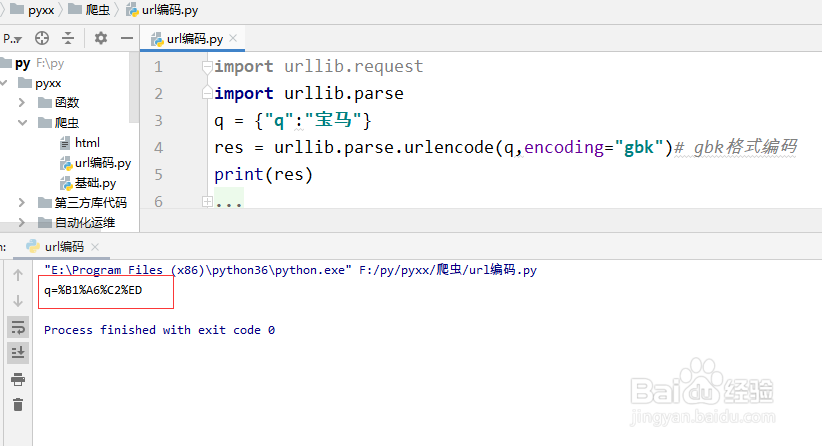
3、上面的字典设置好后,我们将字典中的 value值 进行编码转换,因为这个站的编码格式为gbk ,所以我们用gbk格式进行编码,代码为:
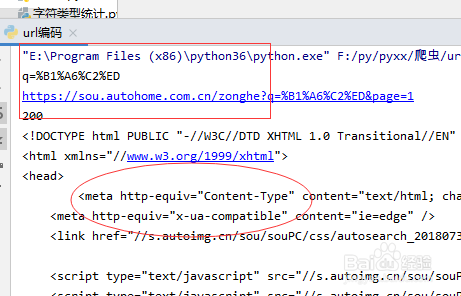
res = urllib.parse.urlencode(q,encoding="gbk")# gbk格式编码
进行打印输入可以看到效果如图
print(res)
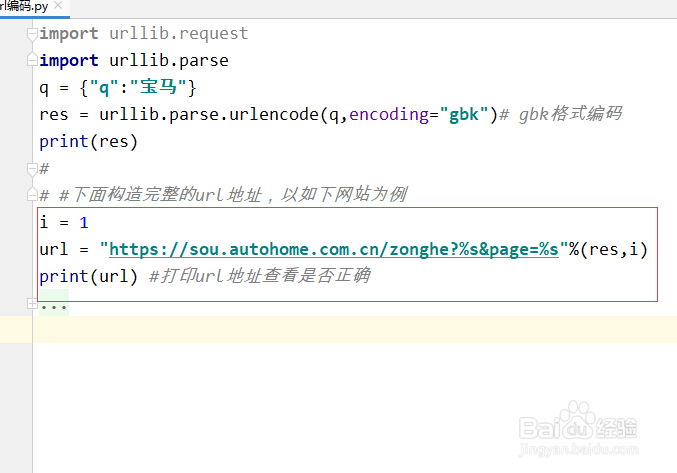
4、接下来我们构造完整的url地址,由于我们是抓取搜索页面,所以需要建立一个代表页码的变量i ,具体如下代码:
i = 1
url = "https://sou.autohome.com.cn/zonghe?%s&page=%s"%(res,i)
这里我们把url地址中的关键词部分和代码页码部分的字符用res和变量i 代替
5、打印输入url地址,并且再浏览器中打开,测试是否正确,效果如图
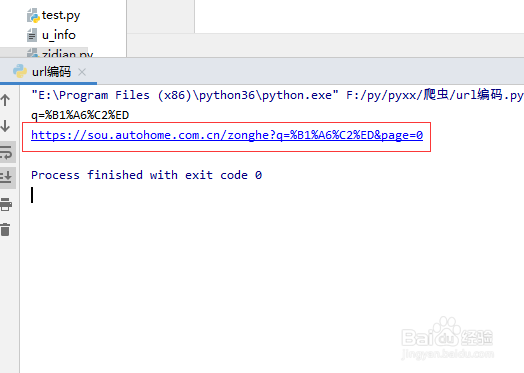
6、接下来我们进行发送请求,并且查看请求状态是否正确,具体代码为:
res2 = urllib.request.urlopen(url) #发送请求
print(res2.status) # 查看请求状态
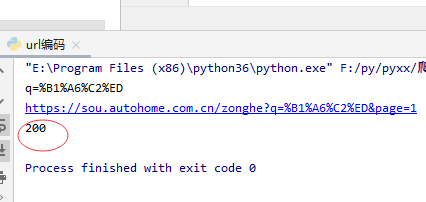
7、最后我们用gbk编码进行源码读取并且打印出结果,代码为:
web = res2.read().decode("gbk")
print(web) #打印出源码
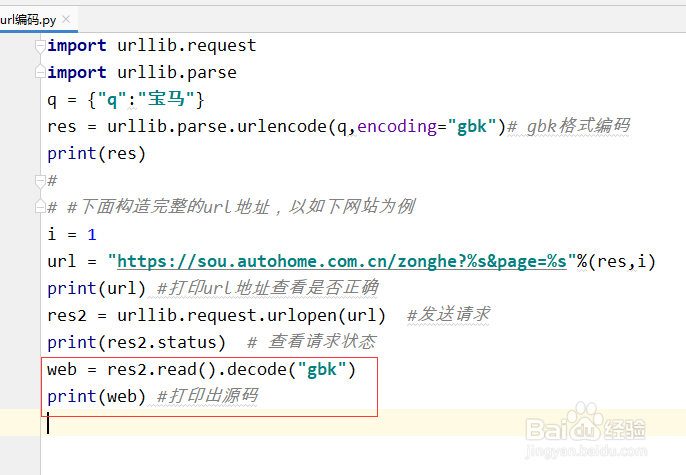
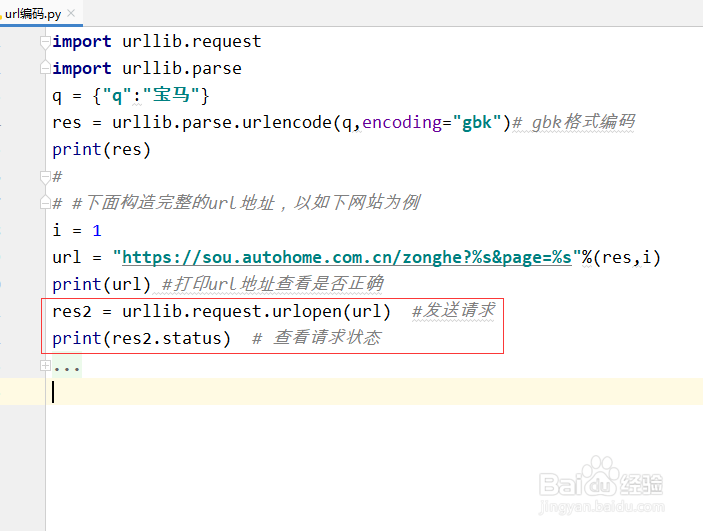
8、整体代码总结和运行效果图:
import urllib.request
import urllib.parse
q = {"q":"宝马"}
res = urllib.parse.urlencode(q,encoding="gbk")# gbk格式编码
print(res)
#
# #下面构造完整的url地址,以如下网站为例
i = 1
url = "https://sou.autohome.com.cn/zonghe?%s&page=%s"%(res,i)
print(url) #打印url地址查看是否正确
res2 = urllib.request.urlopen(url) #发送请求
print(res2.status) # 查看请求状态
web = res2.read().decode("gbk")
print(web) #打印出源码
阅读量:116
阅读量:38
阅读量:135
阅读量:144
阅读量:103