python爬虫的工作步骤
1、1.如下图所示,爬虫从编写的spider文件中的start_urls开始,这个列表中的url就是爬虫抓取的第一个网页,它的返回值是该url对应网页的源代码,我们可以用默认的parse(self,response)函数去打印或解析这个源代码

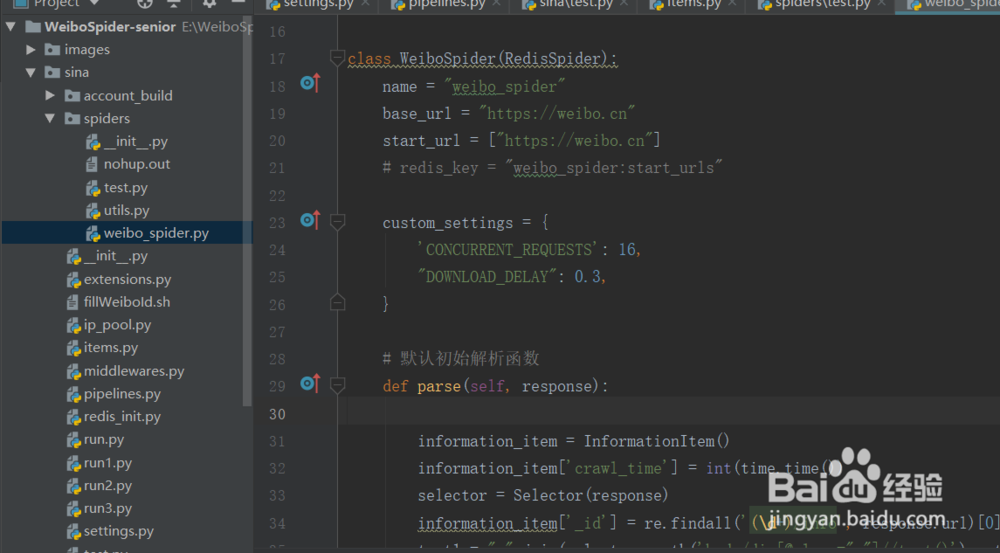
2、2.我们获取到源代码之后,就可以从网页源代码中找到我们想要的信息或需要进一步访问的url,提取信息这一步,scrapy中集成了xpath,正则(re),功能十分强大,提取到信息之后会通过yield进入到中间件当中。

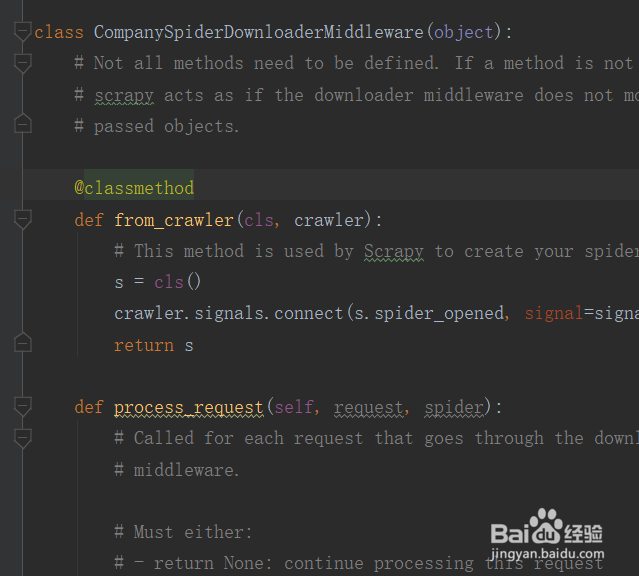
3、中间件包括爬虫中间件和下载中间件,爬虫中间件主要用于设置处理爬虫文件中的代码块,下载中间件主要用于判断爬虫进入网页前后的爬取状态,在此中间件中,你可以根据爬虫的返回状态去做进一步判断。

4、最后我们将yield过来的item,即就是我们想要的数据会在pipeline.py文件中进行处理,存入数据库,写入本地文件,都可以在这里进行,另外,为了减少代码冗余,建议所有与设置参数有关的参数,都写在settings.py中去

阅读量:25
阅读量:110
阅读量:143
阅读量:86
阅读量:147